
Postgres Locking Revealed
Locking is a very important part of PostgreSQL (as well as most of other modern RDBMS). It should be familiar to every developer of DB applications (especially to those who are working on highly concurrent code). Locking is mostly addressed and researched when some problem arises. In most cases, these problems relate to deadlock or data inconsistency due to misunderstanding how locking works in Postgres. Despite its importance, locking mechanism in Postgres is poorly documented and doesn’t even work as expected in some cases (as documentation suggests). I will hereby try to present everything we should know in order to work with Postgres, having in mind locking mechanisms as well as faster resolution of locking issues.
What Does Documentation Say?
Generally in Postgres we have 3 mechanisms of locking: table-level, row-level and advisory locks. Table and row level locks can be explicit or implicit. Advisory locks are mainly explicit. Explicit locks are acquired on explicit user requests (with special queries) and implicit are acquired by standard SQL commands.
In addition totableandrowlocks,page-level share/exclusivelocks are used to control read/write access to table pages in the shared buffer pool. These locks are released immediately after a row is fetched or updated. Application developers normally need not be concerned with page-level locks.
Locking mechanisms have changed in time, so I will cover locking in 9.x versions of Postgres. Versions 9.1 and 9.2 are mainly the same, and versions 9.3 and 9.4 have some differences mainly connected to row-level locking.
Table-level Locks
Most of the table-level locks are acquired by built-in SQL commands, but they can also be acquired explicitly with LOCK command. Available table-level locks are:
ACCESS SHARE– The SELECT command acquires this lock on table(s) referenced in query. General rule is that all queries that only read table acquire this lock.ROW SHARE– The SELECT FOR UPDATE and SELECT FOR SHARE commands acquire this lock on target table (as well as ACCESS SHARE lock on all referenced tables in query).ROW EXCLUSIVE– The UPDATE, INSERT and DELETE commands acquire this lock on target table (as well as ACCESS SHARE lock on all referenced tables in query). General rule is that all queries that modify table acquire this lock.SHARE UPDATE EXCLUSIVE– The VACUUM (without FULL), ANALYZE, CREATE INDEX CONCURRENTLY, and some forms of ALTER TABLE commands acquire this lock.SHARE– The CREATE INDEX command acquires lock on table referenced in query.SHARE ROW EXCLUSIVE– Not acquired implicitly by any command.EXCLUSIVE– This lock mode allows only reads to process in parallel with transaction that acquired this lock. It is not acquired implicitly by any command.ACCESS EXCLUSIVE– The ALTER TABLE, DROP TABLE, TRUNCATE, REINDEX, CLUSTER, and VACUUM FULL commands acquire lock on table referenced in query. This mode is default mode of LOCK command.
It is important to know that all these locks are table-level locks, even if they have ROW in their name.The most important info for every mode is the list of modes which are in conflict with each other. Two transactions can’t hold locks on conflicting modes on the same table at the same time. Transaction is never in conflict with itself. Non-conflicting locks can be held concurrently by many transactions. It is also important to know that there are self-conflicting modes. When some lock mode is acquired it is held until end of transaction. But if a lock is acquired after establishing a savepoint, the lock is released immediately if the savepoint is rolled back to. Here is the table which shows which modes are in conflict with each other:
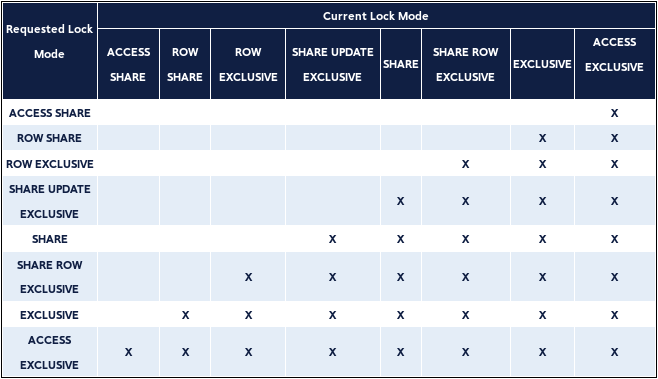
Row-level Locks
In Postgres 9.1 and 9.2 there are two row-level lock modes, but on Postgres 9.3 and 9.4 there are four modes.
Postgres doesn’t remember any information about modified rows in memory, so there is no limit on the number of rows locked at one time. However, locking a row might cause a disk write, e.g., SELECT FOR UPDATE modifies selected rows to mark them locked, and so will result in disk writes.ROW-LEVEL LOCKS IN POSTGRES 9.1 AND 9.2
In these versions there are only two kinds of row-level locks: exclusive or share lock. An exclusive row level lock is automatically acquired when row is updated or deleted. Row-level locks don’t block data querying, they block just writes to the same row. Exclusive row-level lock can be acquired explicitly without the actual changing of the row with SELECT FOR UPDATE command.
Share row-level lock can be acquired with SELECT FOR SHARE command. A shared lock does not prevent other transactions from acquiring the same shared lock. However, no transaction is allowed to update, delete, or exclusively lock a row on which any other transaction holds a shared lock.
ROW-LEVEL LOCKS IN POSTGRES 9.3 AND 9.4
In Postgres 9.3 and 9.4 there are four types of row-level locks:
FOR UPDATE– This mode causes the row fetched withSELECTto be locked for update.This prevents them from being locked, modified or deleted by other transactions. That is, other transactions that attempt UPDATE, DELETE, SELECT FOR UPDATE, SELECT FOR NO KEY UPDATE, SELECT FOR SHARE or SELECT FOR KEY SHARE of these rows will be blocked. This mode is also acquired by DELETE on a row, and also UPDATE of some columns (currently the set of columns considered are those that have unique index on them that can be used as foreign key – but this may change in future)FOR NO KEY UPDATE– This mode is similar asFOR UPDATEbut it is weaker – it will not blockSELECT FOR KEY SHARElock mode. It is acquired byUPDATEcommand that doesn’t acquireFOR UPDATElock.FOR SHARE– This mode is similar asFOR NO KEY UPDATEexcept it acquires share lock (not exclusive). A shared lock blocks other transactions from performing UPDATE, DELETE, SELECT FOR UPDATE or SELECT FOR NO KEY UPDATE on these rows, but it does not prevent them from performing SELECT FOR SHARE or SELECT FOR KEY SHARE.FOR KEY SHARE– Behaves similarly to FOR SHARE, except that the lock is weaker: SELECT FOR UPDATE is blocked, but not SELECT FOR NO KEY UPDATE. A key-shared lock blocks other transactions from performing DELETE or any UPDATE that changes the key values, but doesn’t prevent any other UPDATE, nor SELECT FOR NO KEY UPDATE, SELECT FOR SHARE, or SELECT FOR KEY SHARE.
Conflicts on row-level locks:
| CURRENT LOCK MODE | ||||
|---|---|---|---|---|
| FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE | |
| FOR KEY SHARE | x | |||
| FOR SHARE | x | x | ||
| FOR NO KEY UPDATE | x | x | x | |
| FOR UPDATE | x | x | x | x |
Advisory Locks
Postgres provides a means for creating locks that have application-defined meanings. These are called advisory locks, because the system does not enforce their use — it is up to the application to use them correctly.
There are two ways to acquire an advisory lock in Postgres: at session level or at transaction level. Once acquired at session level, an advisory lock is held until explicitly released or the session ends. Unlike standard lock requests, session-level advisory lock requests do not honor transaction semantics: a lock acquired during a transaction that is later rolled back will still be held following the rollback, and likewise an unlock is effective even if the calling transaction fails later. A lock can be acquired multiple times by its owning process; for each completed lock request there must be a corresponding unlock request before the lock is actually released. Transaction-level lock requests, on the other hand, behave more like regular lock requests: they are automatically released at the end of the transaction, and there is no explicit unlock operation. This behavior is often more convenient than the session-level behavior for short-term usage of an advisory lock. Session-level and transaction-level lock requests for the same advisory lock identifier will block each other in the expected way. If a session already holds a given advisory lock, additional requests by it will always succeed, even if other sessions are awaiting the lock; this statement is true regardless of whether the existing lock hold and new request are at session level or transaction level. Complete list of functions for manipulating advisory locks can be found in documentation.
Here are some samples with acquiring transaction level exclusive advisory locks (pg_locks is system view, described latter in this post. It holds information about transaction holding table-level and advisory locks.):
Open first psql session, open a transaction and acquire an advisory lock:
-- Transaction 1
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- Some work hereNow open a second psql session and run a new transaction on the same advisory lock:
-- Transaction 2
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- This transaction is now blockedIn the third psql session we can check check what this lock looks like:
SELECT * FROM pg_locks;
-- Only relevant parts of output
locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted |fastpath
---------------+----------+----------+------+-------+------------+---------------+---------+-------+----------+--------------------+-------+---------------------+---------+----------
advisory | 16393 | | | | | | 0 | 1 | 1 | 4/36 | 1360 | ExclusiveLock | f | f
advisory | 16393 | | | | | | 0 | 1 | 1 | 3/186 | 14340 | ExclusiveLock
```-- Transaction 1
COMMIT;
-- This transaction now released lock, so Transaction 2 can continueWe can also make a call to non-blocking methods for acquiring locks. These methods will try to acquire lock, and return true (if they succeeded in that) or false (if lock can’t be acquired).
-- Transaction 1
BEGIN;
SELECT pg_advisory_xact_lock(1);
-- Some work here-- Transaction 2
BEGIN;
SELECT pg_try_advisory_xact_lock(1) INTO vLockAcquired;
IF vLockAcquired THEN
-- Some work
ELSE
-- Lock not acquired
END IF;-- Transaction 1
COMMIT;and now some practice…
Monitoring Locks
Base station for monitoring locks held by all active transactions is pg_locks system view. This view contains one row per active lockable object, requested lock mode and relevant transaction. What is very important to know is that pg_locks holds info about locks that are tracked in memory, so it doesn’t show row-level locks! This view shows table-level and advisory locks. If a transaction is waiting for a row-level lock, it will usually appear in the view as waiting for the permanent transaction ID of the current holder of that row lock. This is something which makes debugging of row level locks much harder. In fact, you will not see row level locks anywhere, until someone blocks the transaction that holds it (then you will see a tuple that is locked in pg_locks table). pg_locks is not very readable view (not very human friendly) so lets make our view which will show locking information more acceptable to us:
-- View with readable locks info and filtered out locks on system tables
CREATE VIEW active_locks AS
SELECT clock_timestamp(), pg_class.relname, pg_locks.locktype, pg_locks.database,
pg_locks.relation, pg_locks.page, pg_locks.tuple, pg_locks.virtualtransaction,
pg_locks.pid, pg_locks.mode, pg_locks.granted
FROM pg_locks JOIN pg_class ON pg_locks.relation = pg_class.oid
WHERE relname !~ '^pg_' and relname <> 'active_locks';
-- Now when we want to see locks just type
SELECT * FROM active_locks;Now we have a playground for some experiments…
Simple Examples
Let’s create some tables for practicing:
CREATE TABLE parent (
id serial NOT NULL PRIMARY KEY,
name text NOT NULL
);
CREATE TABLE child (
id serial NOT NULL PRIMARY KEY,
parent_id int4 NOT NULL,
name text NOT NULL,
CONSTRAINT child_parent_fk FOREIGN KEY (parent_id) REFERENCES parent(id)
);and try some simple transactions to check how locking looks like:
BEGIN;
SELECT * FROM active_locks; -- There are no active locks yet
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
-----------------+---------+----------+----------+----------+------+-------+--------------------+-----+------+---------
(0 rows)
INSERT INTO parent (name) VALUES ('Parent 1');
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
----------------------------+---------------+----------+----------+----------+------+-------+--------------------+------+------------------+---------
2015-04-12 13:43:02.896+02 | parent_id_seq | relation | 16393 | 16435 | | | 3/150 | 9000 | AccessShareLock | t
2015-04-12 13:43:02.896+02 | parent | relation | 16393 | 16437 | | | 3/150 | 9000 | RowExclusiveLock | t
(2 rows)
COMMIT;
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
-----------------+---------+----------+----------+----------+------+-------+--------------------+-----+------+---------
(0 rows)We can see that after inserting one row in parent table, we acquired ROW EXCLUSIVE lock on parent table. parent_id_seq is sequence for parent’s primary key. As this relations is selected (as table) we acquired ACCESS SHARE lock on it.
Let’s try to insert something in child table;
BEGIN;
INSERT INTO child (parent_id, name) VALUES (1, 'Child 1 Parent 1');
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
---------------------------+--------------+----------+----------+----------+------+-------+--------------------+------+------------------+---------
2015-04-12 13:50:48.17+02 | parent_pkey | relation | 16393 | 16444 | | | 3/152 | 9000 | AccessShareLock | t
2015-04-12 13:50:48.17+02 | parent | relation | 16393 | 16437 | | | 3/152 | 9000 | RowShareLock | t
2015-04-12 13:50:48.17+02 | child_id_seq | relation | 16393 | 16446 | | | 3/152 | 9000 | AccessShareLock | t
2015-04-12 13:50:48.17+02 | child | relation | 16393 | 16448 | | | 3/152 | 9000 | RowExclusiveLock | t
(4 rows)
COMMIT;Now the situation is more interesting. We can see additional ROW SHARE lock on parent table. What we can’t see here is that this INSERT also acquired row-level share lock on row referenced in parent table. We can see this with executing two transactions in parallel:
-- Transaction 1
BEGIN;
INSERT INTO child (parent_id, name) VALUES (1, 'Child 2 Parent 1');-- Transaction 2
BEGIN;
DELETE FROM parent WHERE id = 1;Now open a third session and let’s see what our locks look like:
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
----------------------------+--------------+----------+----------+----------+------+-------+--------------------+------+---------------------+---------
2015-04-12 14:18:35.005+02 | parent_pkey | relation | 16393 | 16444 | | | 4/32 | 4428 | RowExclusiveLock | t
2015-04-12 14:18:35.005+02 | parent | relation | 16393 | 16437 | | | 4/32 | 4428 | RowExclusiveLock | t
2015-04-12 14:18:35.005+02 | parent_pkey | relation | 16393 | 16444 | | | 3/153 | 9000 | AccessShareLock | t
2015-04-12 14:18:35.005+02 | parent | relation | 16393 | 16437 | | | 3/153 | 9000 | RowShareLock | t
2015-04-12 14:18:35.005+02 | child_id_seq | relation | 16393 | 16446 | | | 3/153 | 9000 | AccessShareLock | t
2015-04-12 14:18:35.005+02 | child | relation | 16393 | 16448 | | | 3/153 | 9000 | RowExclusiveLock | t
2015-04-12 14:18:35.005+02 | parent | tuple | 16393 | 16437 | 0 | 1 | 4/32 | 4428 | AccessExclusiveLock | t
(7 rows)DELETE query is blocked, waiting for transaction 1 to finish. We can see that it acquired a lock on tuple 1. But why is DELETE query blocked if we can see that all locks are granted? These two transactions are not synchronized on lock on any relation. In fact if one transaction holds a lock on some row that and second transaction asks for that lock, second transaction will then try to acquire SHARE lock on transaction that holds that lock. When first transaction finishes, second transaction will continue. This is possible because each transaction holds EXCLUSIVE lock on itself. We can see this is pg_locks view, and here is the output (just part that is important):
locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted |fastpath
---------------+----------+----------+------+-------+------------+---------------+---------+-------+----------+--------------------+-------+---------------------+---------+----------
transactionid | | | | | | 707 | | | | 3/153 | 9000 | ExclusiveLock | t | f
transactionid | | | | | | 707 | | | | 4/32 | 4428 | ShareLock | f | f
transactionid | | | | | | 708 | | | | 4/32 | 4428 | ExclusiveLock | t | fWe can see that transactions 707 (pid 9000) and 708 (pid 4428) holds EXCLUSIVE lock on their transaction ids, and that transaction 708 tries to acquire SHARE lock on transaction 707.
Now, the most interesting sample. We can play with updating child table but without actually changing anything correlated to parent table (in this case parent_id column).
BEGIN;
UPDATE child SET name = 'My new name' WHERE id = 1;
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
----------------------------+------------+----------+----------+----------+------+-------+--------------------+------+------------------+---------
2015-04-14 09:05:42.713+02 | child_pkey | relation | 16393 | 16455 | | | 3/183 | 3660 | RowExclusiveLock | t
2015-04-14 09:05:42.713+02 | child | relation | 16393 | 16448 | | | 3/183 | 3660 | RowExclusiveLock | t
(2 rows)
UPDATE child SET name = 'My new name' WHERE id = 1;
SELECT * FROM active_locks;
clock_timestamp | relname | locktype | database | relation | page | tuple | virtualtransaction | pid | mode | granted
----------------------------+-------------+----------+----------+----------+------+-------+--------------------+------+------------------+---------
2015-04-14 09:05:45.765+02 | parent_pkey | relation | 16393 | 16444 | | | 3/183 | 3660 | AccessShareLock | t
2015-04-14 09:05:45.765+02 | parent | relation | 16393 | 16437 | | | 3/183 | 3660 | RowShareLock | t
2015-04-14 09:05:45.765+02 | child_pkey | relation | 16393 | 16455 | | | 3/183 | 3660 | RowExclusiveLock | t
2015-04-14 09:05:45.765+02 | child | relation | 16393 | 16448 | | | 3/183 | 3660 | RowExclusiveLock | t
(4 rows)
COMMIT;This is very interesting and most important to remember. As we can see we are executing UPDATE query which doesn’t touch anything related to parent table. After first execution we can see that just child table contains table level locks here. Same thing is for row-level locks. Only child table’s row is locked FOR UPDATE. This is optimization that exists in Postgres. If locking manager can figure out from the first query that foreign key is not changed (it is not mentioned in update query or is set to same value) it will not lock parent table. But in second query it will behave as it is described in documentation (it will lock parent table in ROW SHARE locking mode and referenced row in FOR SHARE mode). This is very dangerous because it can lead to the most dangerous and hardest to find deadlocks. We can use explicit locking at the beggining of transaction to avoid this. Behavior is different on Postgres 9.1 and 9.2 on one side, and 9.3 and 9.4 on another. The difference is related to row level locking. Postgres 9.3 and 9.4 will acquire weaker FOR KEY SHARE locking mode on parent table. This locking mode is not in conflict with FOR NO KEY UPDATE mode so they can be acquired in parallel by two transactions. This is much better, so there is less chance for deadlocks in 9.3 and 9.4.
The best way to prevent deadlocks, when we are aware they can happen between two transactions, is to acquire row level locks in some order (for example ordered by primary key) and to acquire most restrictive locks first. Having in mind Postgres optimization with locking described in previous paragraph, explicit locking is sometimes the only way to avoid deadlocks.
Once a deadlock happens in Postgres, it will clear it by aborting one of the transactions involved in deadlock. Exactly which transaction will be aborted is difficult to predict and should not be relied upon.
Takeaways
It is very important to have in mind how locking in Postgres works. Deadlocks in highly concurrent environments are probably unavoidable but it is important to know how to discover, monitor and resolve them. Even doing everything “by the book” will not always resolve all possible issues about locking but will reduce them and make them easier to fix. Table-level locks are viewable through pg_locks system view, but row-level locks are not, so this makes locks debugging much harder, so I hope this will be possible in future Postgres versions.

No comments:
Post a Comment
It’s all about friendly conversation here at small review :) I’d love to be hear your thoughts!
Be sure to check back again because I do make every effort to reply to your comments here.