
New Features in SQL Server 2012
In this tutorial I will discuss 10 exciting new features related to developer and SQL Server enhancements. If you've implemented Column Store Indexes, Sequence Objects and a BI solution or are interested in implementing one, you should seriously consider upgrading to SQL Server 2012. These new features will lead to projects with a shorter completion time, faster performance and so on.
I've listed my top 10 favorite SQL Server 2012 features and improvements.
- Column Store Indexes
- Business Intelligence
- Sequence Objects
- Windows Server Core Support
- Pagination
- Error Handling
- New T-SQL Functions
- Enhanced Execute Keyword with WITH RESULT SETS
- User-Defined Server Roles
- Metadata Discovery Enhancements
1. Column Store Indexes
SQL Server 2012 introduced a new feature Column store indexes that can be used to improve query performance. It is used in data warehousing. You can get this feature when you right-click on the indexes folder as "Non-Clustered Column store Index", as shown in the following figure. The column storage is the ability to read the values of a specific column of a table without having to read the values of all the other columns. In row-oriented storage this is impossible because the individual column values are physically stored grouped in rows on the pages and reading a page in order to read a column value must fetch the entire page in memory.
Creating Column store indexes programmatically
Syntax
CREATE NONCLUSTERED COLUMNSTORE INDEX <IndexName> ON <TableName>(Col1,Col2,....Coln)
Example
- CREATE NONCLUSTERED INDEX INDEX_1 ON PersonalDetail(ID, Name)
2. Business Intelligence
In SQL Server 2012 Microsoft introduced a new model called Business Intelligence Semantic Model (BISM) to support a broad range of reporting and analysis needs. BISM is a relational model. That supports two type of model that meet most of your reporting and analysis needs.
- Multidimensional Model
- Tabular model

Most users are familiar with working with tables and relationships and quickly learn to implement business logic using the Excel like Data Analysis Expressions (DAX) language. It is is built on your existing relational model, making it faster, easier to use and quicker to develop than the multidimensional model. If If you require complex modeling, business logic, or security, or if you need a very large scale solution, multidimensional modeling may be the best solution for your needs.
3. Sequence Objects
To create a sequence of a number in the past, we have used options of IDENTITY. But in SQL Server 2012, there is an interesting option to utilize called Sequence. Sequence is a user-defined object that creates a sequence of a number. It has similar functionality to an identity column. You can create it with SQL Server Management Studio or T-SQL.
Creating Sequence
The following syntax creates a Sequence object:
- CREATE SEQUENCE [schema_name . ] sequence_name
- [ AS [ built_in_integer_type | user-defined_integer_type ] ]
- [ START WITH <constant> ]
- [ INCREMENT BY <constant> ]
- [ { MINVALUE [ <constant> ] } | { NO MINVALUE } ]
- [ { MAXVALUE [ <constant> ] } | { NO MAXVALUE } ]
- [ CYCLE | { NO CYCLE } ]
- [ { CACHE [ <constant> ] } | { NO CACHE } ]
- [ ; ]
- START WITH: Starting number in the sequence
- INCREMENT BY: The incrementing value of the sequence
- MINVALUE: The minimum value the sequence can produce.
- MAXVALUE: The maximum value the sequence can produce.
- CYCLE: If the MAXVALUE is set with the CYCLE, when the MAXVALUE is reached the sequence will cycle to the MINVALUE and start again.
- CACHE: If a CACHE argument is provided, SQL Server will cache (store in memory) the amount of values specified.
Example
Now let's create a sequence similar to an identity column with 1 as increment.
- CREATE SEQUENCE dbo.TestSequence AS BIGINT
- START WITH 5
- INCREMENT BY 1
- MINVALUE 2
- MAXVALUE 9
- CYCLE
- CACHE 10;
Now creating a table.
- CREATE table TABLEsequenceTest
- (
- ID INT,
- Name nvarchar(100) NOT NULL
- )
NEXT VALUE FOR
The new NEXT VALUE FOR T-SQL keyword is used to get the next sequential number from a Sequence.
Now insert some data into the table.
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Jimmy');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Rahul Kumar');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Manish');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Jimmy');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Rahul Kumar');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Manish');
- INSERT TABLEsequenceTest (ID, Name)VALUES (NEXT VALUE FOR TestSequence, 'Jimmy');
Now use the select statement to see the table data:
- SELECT * FROM TABLEsequenceTest
The results would look like this:

In the preceding image the maxvalue is 9. When the MAXVALUE is reached the sequence will cycle to the MINVALUE(2) and start again.
Relate Sequence object to a table
In this example we see how to relate a Sequence object to a table. We have already created a sequence named TestSequence. Now create a new table to define a sequence as an Identity column with the table; see:
- CREATE TABLE TABLEsequenceTest2
- (
- Id INT default (next value for dbo.TestSequence),
- Name VARCHAR(50) NOT NULL
- )
Now insert some data into the table:
- INSERT TABLEsequenceTest2 (Name)VALUES ('Jimmy');
- INSERT TABLEsequenceTest2 (Name)VALUES ('Rahul Kumar');
- INSERT TABLEsequenceTest2 (Name)VALUES ('Manish');
Now use a select statement to see the table data:
- SELECT * FROM TABLEsequenceTest2
The results would look like this:

To delete a sequence using Drop keyword
DROP SEQUENCE TestSequence
Resetting Sequence using Alter keyword
Argument 'START WITH' cannot be used in an ALTER SEQUENCE statement. Restart with is used instead of start with.
- Alter SEQUENCE dbo.TestSequence
- RESTART WITH 2
- INCREMENT BY 1
- MINVALUE 2
- MAXVALUE 9
- CYCLE
- CACHE 10;
- GO
To see all sequences available in a database
- SELECT * FROM SYS.SEQUENCES
Now press F5 to see all the sequences available in a database, as in:

Difference between Sequence and Identity
A Sequence object is similar in function to an identity column. But a big difference is:
- Identity: A value retrieved from an Identity is tied to a specific table column.
- Sequence: A value retrieved from a Sequence object is not tied to a specific table column. That means one Sequence number can be used across multiple tables.
4. Windows Server Core Support
The Windows Server Core has been around since Windows Server 2008. But could not do so because it wasn't officially supported. It is supported in SQL Server 2012. This is also a important new feature of SQL Server 2012. when we run a previous version of SQL Server on Windows Server Core always seemed difficult. SQL Server 2012's support for Windows Server Core enables leaner and more efficient SQL Server installations and also reduces potential attack vectors and the need for patching. So when we talk about SQL Server we would love to run it over an operating system with minimal features enabled. Windows Server Core is designed for infrastructure applications such as SQL Server that provide back-end services but don't need a GUI on the same server. That means It is a GUI-less version of the Windows operating system.
5. Pagination
In the earlier versions of SQL Server, if you use a GridView then you set its pagination property. However if you want to do this from the server side then you need to use the row_number() function and supply the specific range of rows and also retrieve the current page data from the database using a temp table. The ORDER BY OFFSET and FETCH NEXT ONLY keywords are one of the major features introduced in SQL Server 2012.
- Create TABLE UserDetail
- (
- User_Id int NOT NULL IDENTITY(1,1),
- FirstName varchar(20),
- LastName varchar(40) NOT NULL,
- Address varchar(255),
- PRIMARY KEY (User_Id)
- )
- INSERT INTO UserDetail(FirstName, LastName, Address)
- VALUES ('Smith', 'Kumar','Capetown'),
- ('Crown', 'sharma','Sydney'),
- ('Copper', 'verma','Jamaica'),
- ('lee', 'verma','Sydney'),
- ('Rajesh', 'Kumar','India'),
- ('Rahu', 'sharma','India'),
- ('Ravi', 'verma','Jamaica'),
- ('Leon', 'verma','Sydney'),
- ('Methews', 'Anglo','Srilanka'),
- ('Ben', 'lon','Newzealand'),
- ('Derrin', 'summy','Jamaica')
- go
- SELECT * FROM [master].[dbo].[UserDetail]

In SQL Server 2008
In SQL Server 2005/2008, we have been doing this data paging by writing a Stored Procedure or a complex query. Here is a sample of how we were using data paging in SQL Server 2005/2008 using the row_number function with an order by clause:
- SELECT *
- FROM (
- SELECT ROW_NUMBER() OVER(ORDER BY User_Id) AS number, *
- FROM userdetail) AS TempTable
- WHERE number > 0 and number <= 4
The ROW_NUMBER function enumerates the rows in the sort order defined in the over clause.
Now using OFFSET and FETCH NEXT Keywords
OFFSET Keyword: If we use offset with the order by clause then the query will skip the number of records we specified in OFFSET n Rows.
- Select *
- from userdetail
- Order By User_Id
- OFFSET 5 ROWS
In the preceding example, we used OFFSET 5 ROWS, so SQL will skip the first 5 records from the result and display the rest of all the records in the defined order. Now select the query and press F5 to execute the query:
Output

FETCH NEXT Keywords: When we use Fetch Next with an order by clause only, without Offset then SQL will generate an error.
- SELECT *
- FROM userdetail
- ORDER BY User_Id
- --OFFSET 5 ROWS
- FETCH NEXT 10 ROWS ONLY;
Output

ORDER BY OFFSET and FETCH NEXT
In this example, query guides how to use both ORDER BY OFFSET and FETCH NEXT with a select statement for creating paging in SQL Server 2012.
- SELECT *
- FROM userdetail
- ORDER BY User_Id
- OFFSET 5 ROWS
- FETCH NEXT 8 ROWS ONLY;
Output

Paging with Stored Procedure
In this example we are creating a Stored Procedure with both an ORDER BY OFFSET and FETCH NEXT keyword to enhancement the paging in SQL Server 2012.
- CREATE PROCEDURE TestPaging
- (
- @PageNumber INT,
- @PageSize INT
- )
- AS
- DECLARE @OffsetCount INT
- SET @OffsetCount = (@PageNumber-1)*@PageSize
- SELECT *
- FROM [UserDetail]
- ORDER BY [User_Id]
- OFFSET @OffsetCount ROWS
- FETCH NEXT @PageSize ROWS ONLY
Now execute the Stored Procedure and provide the page number and page size to test paging.
EXECUTE TestPaging 1,5
In the preceding query:
1: This is for the first page
5: Number of records to display on the page
Output

EXECUTE TestPaging 2,5
In the preceding query:
2: This is for the second page
5: Number of records to display on the page
Output

6. Error Handling
If you have programmed in languages like C# or other similar languages then you are probably familiar with the try, catch and throw statements. Transact-SQL also gives you this option to find an exception using a try/catch block. In SQL Server 2005/2008, RAISERROR has remained the only mechanism for generating your own errors. In SQL Server 2012, a new THROW statement is used to raise exceptions in your T-SQL code instead of RAISERROR. So let's have a look at a practical example. The example is developed in SQL Server 2012 using the SQL Server Management Studio.
In SQL Server 2005/2008
In SQL Server 2005/2008, if you want to re-throw an error in a catch block of a TRY CATCH statement, you need to use RAISERROR with ERROR_MESSAGE() and ERROR_SEVERITY(). But in SQL Server 2012 you can use only a THROW statement to re-throw an error in a catch block of a TRY CATCH statement.
Example 1
In this example we use a select statement in a try block. If there is an error in a try block then it will throw the error to the catch block. The following is a sample T-SQL script with exception handling in SQL Server 2008:
- BEGIN TRY
- select from UserDetail -- select statement error
- END TRY
- BEGIN CATCH
- DECLARE @ErrorMessage nvarchar(4000), @ErrorSeverity int
- SELECT @ErrorMessage = ERROR_MESSAGE(), @ErrorSeverity = ERROR_SEVERITY()
- RAISERROR (@ErrorMessage, @ErrorSeverity, 1 )
- END CATCH
Now press F5 to execute it; the results will be:

Example 2
We divide a number by zero:
- BEGIN TRY
- DECLARE @VALUE INT
- SET @VALUE = 12/ 0
- END TRY
- BEGIN CATCH
- DECLARE @ErrorMessage nvarchar(4000), @ErrorSeverity int
- SELECT @ErrorMessage = ERROR_MESSAGE(), @ErrorSeverity = ERROR_SEVERITY()
- RAISERROR ( @ErrorMessage, @ErrorSeverity, 1 )
- END CATCH
Now press F5 to execute it; the results will be:

Now using a THROW statement instead of a RAISERROR:
- BEGIN TRY
- select * from UserDetail
- END TRY
- BEGIN CATCH
- throw
- END CATCH
Now press F5 to execute it.

In SQL Server 2012
In SQL Server 2012, THROW can appear only inside a CATCH block. In SQL Server 2012 you can only use a THROW statement in a catch block when an unexpected error occurs in a TRY block. A new THROW statement is used to raise exceptions in your T-SQL code instead of RAISERROR. In SQL Server 2012, by using the Throw keyword, the preceding script will be changed to this:
Example 1 ( Using THROW Statement)
- BEGIN TRY
- select from UserDetail -- select statement error
- END TRY
- BEGIN CATCH
- throw
- END CATCH
Now press F5 to execute it; the results will be:

Example 2 ( Using THROW Statement)
We divide a number by zero. A THROW statement is used to raise exceptions; see:
- BEGIN TRY
- DECLARE @VALUE INT
- SET @VALUE = 12/ 0
- END TRY
- BEGIN CATCH
- throw
- END CATCH
Now press F5 to execute it; the results will be:

7. Programmability Enhancements: New T-SQL Functions
There are many new new functions added to SQL Server 2012. In this article I have described all the functions listed below.
Logical Functions
- CHOOSE (Transact-SQL)
- IIF (Transact-SQL)
Conversion Functions
- PARSE (Transact-SQL)
- TRY_PARSE (Transact-SQL)
- TRY_CONVERT (Transact-SQL)
Date and time Functions
- DATEFROMPARTS Function
- TIMEFROMPARTS Function
- DATETIMEFROMPARTS Function
- EMONTH Function .. and so on
String Functions
- FORMAT (Transact-SQL)
- CONCAT (Transact-SQL)
Analytic Functions
- First_Value Function
- Last_Value Function
So let's have a look at a practical example of all the new SQL Server functions. The example is developed in SQL Server 2012 using the SQL Server Management Studio.
First now start with Logical Functions.
Logical Function
IIF() Function
The IIF function is used to check a condition. Suppose X>Y. In this condition a is the first expression and b is the second expression. If the first expression evaluates to TRUE then the first value is displayed, if not the second value is displayed.
Syntax
IIF ( boolean_expression, true_value, false_value )
Example
- DECLARE @X INT;
- SET @X=50;
- DECLARE @Y INT;
- SET @Y=60;
- Select iif(@X>@Y, 50, 60) As IIFResult
In this example X=50 and Y=60; in other words the condition is false. Select iif(@X>@Y, 50, 60) As IIFResult returns false value that is 60.
Output

Choose() Function
This function returns a value out of a list based on its index number. You can think of it as an array kind of thing. The Index number here starts from 1.
Syntax
CHOOSE ( index, value1, value2.... [, valueN ] )
CHOOSE() Function excepts two parameters,
- Index: Index is an integer expression that represents an index into the list of the items. The list index always starts at 1.
- Value: List of values of any data type.
The following are some facts related to the Choose Function.
- Item index starts from 1In the preceding example we use index=5. It will start at 1. Choose() returns T as output since T is present at @Index location 5.
- DECLARE @ShowIndex INT;
- SET @ShowIndex =5;
- Select Choose(@ShowIndex, 'M','N','H','P','T','L','S','H') As ChooseResult
Output
- When passed a set of types to the function it returns the data type with the highest precedence; see:In this example we use index=5. It will start at 1. Choose() returns 15.0 as output since 15 is present at @ShowIndex location 5 because in the item list, fractional numbers have higher precedence than integers.
- DECLARE @ShowIndex INT;
- SET @ShowIndex =5;
- Select Choose(@ShowIndex ,35,42,12.6,14,15,18.7) As CooseResult

- If an index value exceeds the bound of the array it returns NULLIn this example we use index=9. It will start at 1. Choose() returns Null as output because in the item list the index value exceeds the bounds of the array; the last Index=8.
- DECLARE @ShowIndex INT;
- SET @ShowIndex =9;
- Select Choose(@ShowIndex , 'M','N','H','P','T','L','S','H') As CooseResult
Output
- If the index value is negative then that exceeds the bounds of the array therefore it returns NULL; see:In this example we use index= -1. It will start at 1. Choose() returns Null as output because in the item list the index value exceeds the bounds of the array.
- DECLARE @ShowIndex INT;
- SET @ShowIndex =-1;
- Select Choose(@ShowIndex, 'M','N','H','P','T','L','S','H') As CooseResult
Output
- If the provided index value has a float data type other than int, then the value is implicitly converted to an integer; see:In this example we use index= 4.5. It will start at 1. If the specified index value has a float data type other than int, then the value is implicitly converted to an integer. It returns the 13.0 as output since 15 is present at @ShowIndex=4.5 that means index is 4.
- DECLARE @ShowIndex INT;
- SET @ShowIndex =4.5;
- Select Choose(@ShowIndex ,35,42,12.6,13,15,20) As CooseResult
Output
Conversion Functions
- Parse Function
This function converts a string to Numeric and Date and Time formats. It will raise an error if translation isn't possible. You may still use CAST or CONVERT for general conversions. It depends on the presence of the CLR.
Syntax
To demonstrate this new conversion function the following defines the syntax:
PARSE ( string_value AS data_type [ USING culture ] )
The Parse Function contains three parameters. The Culture part of the function is optional.
string_value: String value to parse into the Numeric and Date and Time format.
data_type: Returns data type, numeric or datetime type.
culture: Culture part of the function is optional. A language (English, Japanese, Spanish, Danish, French and so on) to be used by SQL Server to interpret data. A culture can be specified if needed; otherwise, the culture of the current session is used. Culture can be any of the .NET supported cultures, not limited to those supported by SQL Server.
For Example
In this example we see the parse function with Cast and Convert functions. Execute the following to convert a string value to datetime using CAST, CONVERT and PARSE functions:Now press F5 to execute those commands. The result the command produces is:- SELECT CAST('6/08/2012' AS DATETIME2) AS [CAST Function Result] -- Using CAST Function GO SELECT CONVERT(DATETIME2, '06/08/2012') AS [CONVERT Function Result] --Using Convert Function Go SELECT PARSE('06/08/2012' AS Datetime2 USING 'en-US') AS [PARSE Function Result] -- Using Parse Function GO

As you will see, only PARSE is able to convert the string value to a datetime and the first two queries that are using CAST and CONVERT will fail as in the following:Now press F5 to execute the preceding commands. The output will be as in the following:- SELECT CAST('Monday, 06 august 2012' AS DATETIME2) AS [CAST Function Result] -- Using CAST Function GO SELECT CONVERT(DATETIME2, 'Monday, 06 august 2012') AS [CONVERT Function Result] --Using Convert Function Go SELECT PARSE('Monday, 06 august 2012' AS Datetime2 USING 'en-US') AS [PARSE Function Result] -- Using Parse Function GO

- SELECT CAST('6/08/2012' AS DATETIME2) AS [CAST Function Result] -- Using CAST Function GO SELECT CONVERT(DATETIME2, '06/08/2012') AS [CONVERT Function Result] --Using Convert Function Go SELECT PARSE('06/08/2012' AS Datetime2 USING 'en-US') AS [PARSE Function Result] -- Using Parse Function GO
- Try_Parse Function
This function works similarly to the parse function except if the conversion is successful then it will return the value as the specified data type. Otherwise it will return a NULL value.
Syntax
TRY_PARSE ( string_value AS data_type [ USING culture ] )
Example
Using Parse FunctionOutput- SELECT Parse ('Sunday, 06 august 2012' AS Datetime2 USING 'en-US') AS [PARSE Function Result] -- Using Parse Function

Now Using Try_Parse Function- SELECT Try_Parse ('Sunday, 06 august 2012' AS Datetime2 USING 'en-US') AS [Try_PARSE Function Result] -- Using Try_Parse Function GO
- SELECT Parse ('Sunday, 06 august 2012' AS Datetime2 USING 'en-US') AS [PARSE Function Result] -- Using Parse Function
- Try_Convert Function
This is similar to the convert function except it returns null when the conversion fails. If the conversion cannot be completed because the data type of the expression is not allowed to be explicitly converted to the specified data type, an error will be thrown.
Syntax
TRY_CONVERT ( data_type [ ( length ) ], expression [, style ] )
ExampleIn the preceding example the conversion cannot be completed because the data type of the expression is not allowed to be explicitly converted to the specified data type.- SELECT TRY_CONVERT(Datetime2, '06/08/2012') AS [Try_Convert Function Result] -- Using Try_Convert Function
- SELECT TRY_CONVERT(Datetime2, '06/08/2012') AS [Try_Convert Function Result] -- Using Try_Convert Function
Date and time Functions
SQL Server provides many functions for getting date and time values from their parts. You can do that easily using the functions DATEFROMPARTS, TIMEFROMPARTS, DATETIMEFROMPARTS and so on. in SQL Server 2012. Before SQL Server 2012, you need to do many conversions to get the desired results. In this article, you will see how to get date and time values from their parts in SQL Server 2008 conversion.
In SQL Server 2008
To get date and time values from their parts in SQL Server 2008:
- Declare @Year as int=2013
- Declare @Month as int=02
- Declare @Day as int=20
- Select Convert(Date, Convert(varchar(4), @Year) + '-' + Convert(varchar(2), @Month) + '-' + Convert(varchar(2), @Day))
Output

In SQL Server 2012
DATEFROMPARTS Function
The DATEFROMPARTS function returns a date value for the specified year, month, and day. The syntax of the DATEFROMPARTS built-in date function is as follows:
DATEFROMPARTS ( year, month, day )
All three parameters of the DATEFROMPARTS function are required.
year: Integer expression specifying a year.
month: Integer expression specifying a month, from 1 to 12.
day: Integer expression specifying a day.
Example
- Declare @Year as int=2013
- Declare @Month as int=02
- Declare @Day as int=20
- Select DATEFROMPARTS(@Year, @Month, @Day)
Output
2013-02-20
TIMEFROMPARTS Function
The TIMEFROMPARTS function returns time values for the specified time and with the specified precision. The syntax of the TIMEFROMPARTS built-in date function is as follows:
TIMEFROMPARTS ( hour, minute, seconds, fractions, precision)
If the arguments are invalid, then an error is raised. If any of the parameters are null, null is returned.
Example
- Declare @hour as int=58
- Declare @minute as int=46
- Declare @seconds as int=20
- Declare @fractions as int=0
- Declare @precision as int=0
- Select TIMEFROMPARTS(@hour , @minute , @seconds, @fractions , @precision)
Output
58:46:20.0000000
DATETIMEFROMPARTS Function
The DATETIMEFROMPARTS function returns a DateTime value for the specified date and time. The syntax of the DATETIMEFROMPARTS built-in date function is as follows:
DATETIMEFROMPARTS ( year, month, day, hour, minute, seconds, milliseconds)
If the arguments are invalid, then an error is raised. If any of the parameters are null, null is returned.
Example
- Declare @Year as int=2013
- Declare @Month as int=12
- Declare @Day as int=20
- Declare @hour as int=58
- Declare @minute as int=46
- Declare @seconds as int=0
- Declare @milliseconds as int=0
Select DATETIMEFROMPARTS (@Year, @Month, @Day, @hour , @minute , @seconds, @milliseconds)
Output
2013-12-20 58:59:46.0000000
The Eomonth Function
The Eomonth function returns the last day of the month that contains the specified date.
Syntax
The syntax of the "Month" built-in date function is as follows:
MONTH ( startdate [,month_to_add ] )
Here:
The "startdate" parameter can be an expression specifying the date for which to return the last day of the month.
The "month_to_add" is optional.
Example
- Select getdate()asCurrentDate
- Go
- SelectEomonth(getdate())asMonth
- Go
- SelectEomonth('09/12/2012',2)as Month
- Go
- SelectEomonth('09/12/2012')asMonth
Output

String Functions
Format Function
The Format() function is used to format how a field is to be displayed.
Format converts the first argument to a specified format and returns the string value.
Syntax
FORMAT(column_name,format)
where both the field are required.
This function formats the date time. This function is used in the server .NET Framework and CLR. This function will solve many formatting issues for developers.
Example
- DECLARE @d DATETIME = '20/03/2011';
- SELECT FORMAT ( @d, 'd', 'en-US' ) AS US_Result;
Output
20/03/2011
Concat Function
It's the same concatenate function that we use in Excel, it will concatenate two or more strings to make it a single string. It implicitly converts all arguments to string types. This function expects at least two parameters and a maximum of 254 parameters.
Syntax
CONCAT ( string_value1, string_value2 [, string_valueN ] )
String_value: A string value to concatenate to the other values.
Example
- SELECT CONCAT('Rohatash', ' '- 'Kumar') AS [Using concate Function];
Output
Rohatash-Kumar
Analytic Functions
The First_Value and Last_Value are part of the analytic functions. The First_Value function returns the first value in an ordered set of values, and similarly the Last_Value function returns the last value from an ordered set of values.
Creating a table in SQL Server
Now we create a table named employee.
- Create table Employee
- (
- EmpID int,
- EmpName varchar(30),
- EmpSalary int
- )
The following is the sample data for the employee Table.

First_Value Function
The First_Value function is a new analytic function in SQL Server. It returns the first value in an ordered set of values. Here, you will see some examples related to the First_Value function.
Syntax
The following is the SQL Analytic First_Value function syntax:
First_Value ( [scalar_expression )
OVER ([partition_by_clause] order_by_clause)
Scalar_expression: can be a column, subquery, or other expression that results in a single value.
OVER: Specify the order of the rows.
ORDER BY: Provide sort order for the records.
Partition By: Partition by clause is an optional part of the First_Value function and if you don't use it then all the records of the result-set will be considered as being a part of a single record group or a single partition.
Example
Assume the following query:
- Select *, First_value(EmpSalary) OVER (order BY EmpSalary ) as First_ValueResut From Employee
Output

First_Value Function with Partition By Clause
The Partition by clause is an optional part of the First_Value function. By using the PARTITION BY clause with the FIRST_VALUE function we can divide the result set by name.
Example
- Select *, Lead(EmpName) OVER (partition by EmpName ORDER BY EmpName DESC) AS Result From Employee
Output

Last_Value Function
The Last_Value function is also a new analytic function in SQL Server. It returns the last value in an ordered set of values. Here, you will see some examples related to the Last_Value function.
Syntax
The following is the SQL Analytic Last_Value function syntax:
Last_Value ( [scalar_expression )
- OVER ([partition_by_clause] order_by_clause)
- Scalar_expression: can be a column, subquery, or other expression that results in a single value.
- OVER: Specify the order of the rows.
- ORDER BY: Provide sort order for the records.
- Partition By: Partition by clause is a optional part of Last_Value function and if you don't use it all the records of the result-set will be considered as a part of single record group or a single partition and then ranking functions are applied.
Let us see the following query:
- Select *, LAST_VALUE(EmpSalary) OVER(ORDER BY EmpSalary ) AS Last_Salary
- FROM Employee
Output

Last_Value Function with Partition By Clause
The Partition by clause is an optional part of the Last_Value function. By using the PARTITION BY clause with the Last_Value function we can divide the result set by name.
Example
- Select *, LAST_VALUE(EmpSalary) OVER(partition by EmpName ORDER BY EmpSalary ) AS Last_Salary
- FROM Employee
Output

8. Enhanced Execute Keyword with WITH RESULT SETS
The EXECUTE keyword is used to execute a command string. You cannot change the column name and datatype using the execute keyword in SQL Server 2005/2008. You need to modify the Stored Procedure respectively. The previous version of SQL Server only has the WITH RECOMPILE option to force a new plan to be re-compiled. The ability to do that in SQL Server 2012 dramatically improves this part. In SQL Server 2012, there is no need to modify a Stored Procedure. You can change the column name and datatype using the execute keyword.
The table looks as in the following:
- Create TABLE UserDetail
- (
- User_Id int NOT NULL IDENTITY(1,1),
- FirstName varchar(20),
- LastName varchar(40) NOT NULL,
- Address varchar(255),
- PRIMARY KEY (User_Id)
- )
- INSERT INTO UserDetail(FirstName, LastName, Address)
- VALUES ('Smith', 'Kumar','Capetown'),
- ('Crown', 'sharma','Sydney'),
- ('Copper', 'verma','Jamaica'),
- ('lee', 'verma','Sydney')
- go
Now create a Stored Procedure for the select statement in SQL Server 2008:
- Create PROCEDURE SelectUserDetail
- as
- begin
- select FirstName,LastName, Address from UserDetail
- end
- Now use an Execute command to run the stored procedure:
- -- SQL Server 2008
- execute SelectUserDetail
Output

SQL Server 2012
Now we see how to change the column name and datatype using an execute keyword in SQL Server 2012. The previous version of SQL Server only has the WITH RECOMPILE option to force a new plan to be re-compiled. To do that in SQL Server 2012 dramatically improves this part. We change the FirstName to Name and the datatype varchar(20) to char(4). Now execute the following code in SQL Server 2012:
- execute SelectUserDetail
- WITH result SETS
- (
- (
- Name CHAR(4),
- Lastname VARCHAR(20),
- Address varchar(25)
- )
- );
Now Press F5 to run the query and see the result:

New Features in SQL Server 2016
Following are the some of the new features of the Sql Server 2016 which I have blogged. Click on the feature name to know it in detail with extensive list of examples:
1. DROP IF EXISTS Statement in Sql Server 2016
In Sql Server 2016, IF EXISTS is the new optional clause introduced in the existing DROP statement. Basically, it checks the existence of the object, if the object does exists it drops it and if it doesn’t exists it will continue executing the next statement in the batch. Basically it avoids writing if condition and within if condition writing a statement to check the existence of the object.
In Sql Server 2016 we can write a statement like below to drop a Stored Procedure if exists.
--Drop stored procedure if existsDROP PROCEDURE IF EXISTS dbo.WelcomeMessage |
In Sql Server 2016 we can write a statement like below to drop a Table if exists.
--Drop table Customer if existsDROP TABLE IF EXISTS dbo.Customers |
2. STRING_SPLIT function in Sql Server 2016
STRING_SPLIT is one of the new built-in table valued function introduced in Sql Server 2016. This table valued function splits the input string by the specified character separator and returns output as a table.
SYNTAX:
STRING_SPLIT (string, separator) |
Where string is a character delimited string of type CHAR, VARCHAR, NVARCHAR and NCHAR.
Separator is a single character delimiter by which the input string need to be split. The separator character can be one of the type: CHAR(1), VARCHAR(1), NVARCHAR(1) and NCHAR(1).
Result of this function is a table with one column with column name as value.
EXAMPLE: This example shows how we can use STRING_SPLIT function to splits the comma separated string.
SELECT * FROM STRING_SPLIT('Basavaraj,Kalpana,Shree',',') |
RESULT: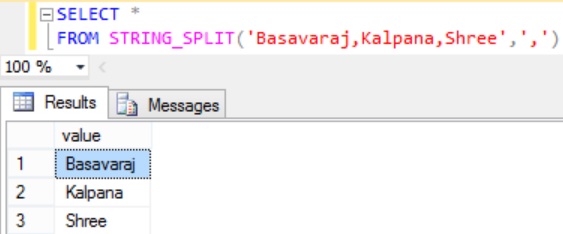
To understand STRING_SPLIT function with extensive list of examples you may like to go through the article: STRING_SPLIT function in Sql Server 2016
3. GZIP COMPRESS and DECOMPRESS functions in Sql Server 2016
COMPRESS and DECOMPRESS are the new built in functions introduced in Sql Server 2016.
COMPRESS function compresses the input data using the GZIP algorithm and returns the binary data of type Varbinary(max).
DECOMPRESS function decompresses the compressed input binary data using the GZIP algorithm and returns the binary data of type Varbinary(max). We need to explicitly cast the output to the desired data type.
These functions are using the Standard GZIP algorithm, so a value compressed in the application layer can be decompressed in Sql Server and value compressed in Sql Server can be decompressed in the application layer.
Let us understand these functions with examples:
Example: Basic Compress and Decompress function examples
SELECT COMPRESS ('Basavaraj') |
RESULT:
0x1F8B0800000000000400734A2C4E2C4B2C4ACC0200D462F86709000000
Let us decompress the above compressed value using the DECOMPRESS function by the following script
SELECT DECOMPRESS( 0x1F8B0800000000000400734A2C4E2C4B2C4ACC0200D462F86709000000) |
RESULT:
0x42617361766172616A
From the above result we can see that the result of the DECOMPRESS function is not the actual value but instead it is a binary data. We need to explicitly cast the result of the DECOMPRESS function to the datatype of the string which is compressed.
Let us cast the result of the DECOMPRESS function to Varchar type by the following statement.
SELECT CAST(0x42617361766172616A AS VARCHAR(MAX)) |
RESULT:
Basavaraj
4. SESSION_CONTEXT in Sql Server 2016
In .Net we have Session object which provides a mechanism to store and retrieve values for a user as user navigates ASP.NET pages in a Web application for that session. With Sql Server 2016 we are getting the similar feature in Sql Server, where we can store multiple key and value pairs which are accessible throughout that session. The key and value pairs can be set by the sp_set_session_context system stored procedure and these set values can be retrieved one at a time by using the SESSION_CONTEXT built in function.
EXAMPLE: This example demonstrates how we can set the session context key named EmployeeId with it’s value and retrieving this set keys value.
--Set the session variable EmployeeId valueEXEC sp_set_session_context 'EmployeeId', 5000--Retrieve the session variable EmployeeId valueSELECT SESSION_CONTEXT(N'EmployeeId') AS EmployeeId |
RESULT:
New Features in SQL Server 2017
SQL Server CONCAT_WS function
The CONCAT_WS function is an enhancement of the already existing CONCAT function, which was introduced in SQL Server 2012. CONCAT allows you to concentrate multiple expressions into one string, where NULL values are treated as an empty string.

However, in many cases the function requires you to type a separator yourself (a single space in the example above). The CONCAT_WS function eliminates this requirement by giving you the option to specify the separator separately (hence WS: with separator):

SQL Server TRANSLATE and TRIM functions
TRANSLATE is in reality a way to replace multiple REPLACE functions at once. The syntax is as follows:
TRANSLATE(inputString,characters,replacements)
The length of the characters expression should be the same as the replacements expression. Let’s illustrate the use of TRANSLATE by cleaning up some text. The following variable contains some non-printable characters:

Normally, to get rid of all those characters you would need to use several REPLACE function calls. LTRIM or RTIM can’t be used, as those characters are in the middle of the text. With TRANSLATE, we can easily remove or replace all the non-wanted characters in one single function call:
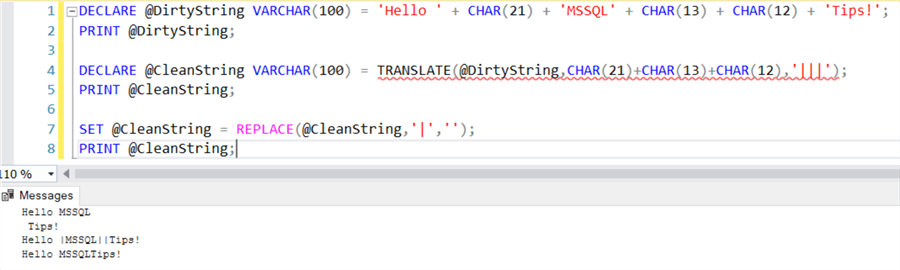
In the example, we replace all the non-printable characters with a special symbol of our choosing: the pipe symbol. After that, we need only one REPLACE function call to replace the pipes with the empty string, returning cleaned-up text string.
Speaking of cleaning up text, another new function is the TRIM function, which is the combination of the LTRIM and RTRIM functions. The following script shows how these functions are used:
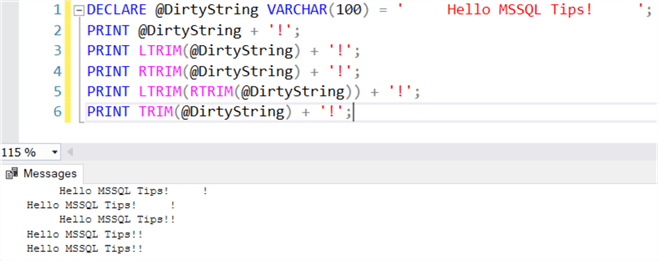
An extra exclamation mark is added to the variable when calling PRINT, to show the possible trailing spaces. Some extra functionality has been added to the TRIM function though, in contrast with LTRIM and RTRIM. You can specify extra characters that need to be removed from the start and the end of the text.

The difference between TRANSLATE and TRIM is that TRIM will only replace characters at the start and the end of the text, while TRANSLATE will search through the entire text. TRIM will also replace characters by the empty string while TRANSLATE will replace characters by other characters specified in the function call.
SQL Server STRING_AGG function
The new STRING_AGG function is the reverse of the STRING_SPLIT function, which was introduced in SQL Server 2016. STRING_AGG concatenates string values using a separator. Let’s illustrate with an example using the AdventureWorks2017 data warehouse. For each product category, we list a concatenated string with all its related product subcategories:
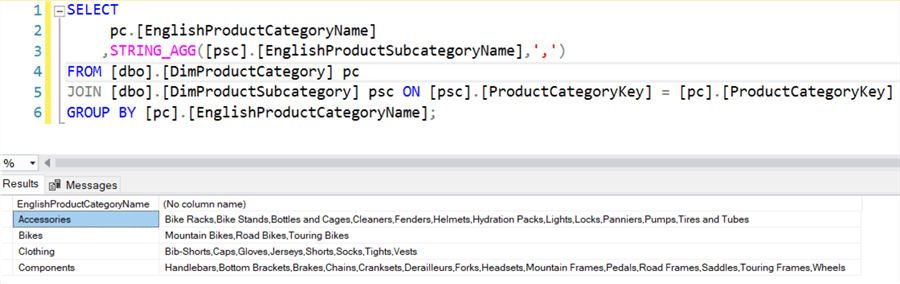
Notice you can also input non-text data types, these will be converted to NVARCHAR.
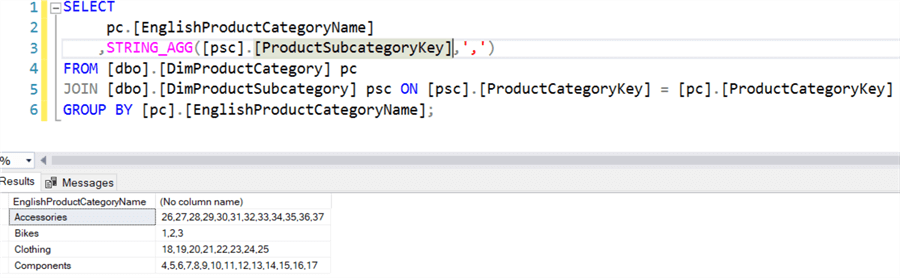
STRING_AGG doesn’t add the separator at the end of the string. By default, the concatenated values are sorted ascending. You can change the sorting order with the WITHIN GROUP clause.
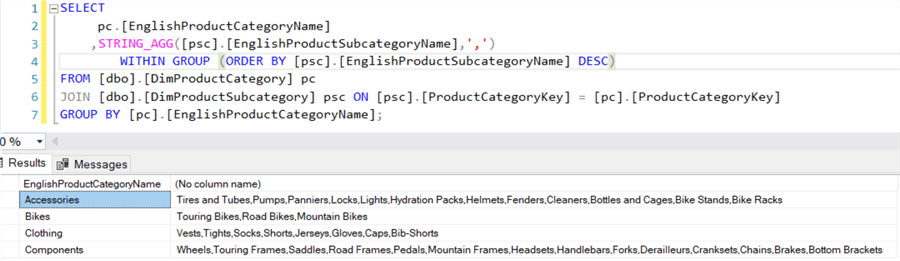
You can also use other expressions to sort the data:
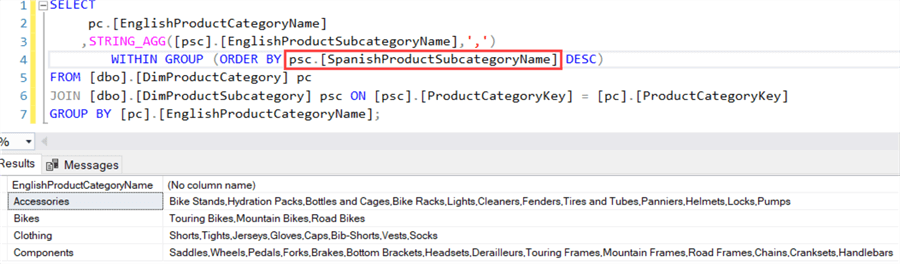
Keep in mind NULL values are ignored by the function. STRING_AGG provides us with a nice built-in method to concatenate string values over rows. In previous versions, this required a bit more coding and some solutions had performance issues over large data sets. You can find a nice overview of different solutions in the article Concatenating Row Values in Transact-SQL. Aaron Bertrand also discusses a good use case for STRING_AGG in the tip Solve old problems with SQL Server’s new STRING_AGG and STRING_SPLIT functions.
Pass Parameters into the STRING_SPLIT Function
STRING_SPLIT parameters can also be passed as variables with different values. In the below script, two variables are declared; one to store the string to be delimited and the second one for the separator value:
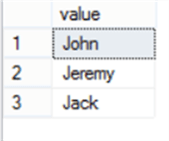
DECLARE @String VARCHAR(50) = 'John,Jeremy,Jack', @Delimiter CHAR(1) =','
SELECT * FROM STRING_SPLIT(@String,@Delimiter)
Executing the previous query, the same result will be returned as follows:
New Features in SQL Server 2019
Approximate COUNT DISTINCT
We all have written queries that use COUNT DISTINCT to get the unique number of non-NULL values from a table. This process can generate a noticeable performance hit especially for larger tables with millions of rows. Many times, there is no way around this. To help mitigate this overhead SQL Server 2019 introduces us to approximating the distinct count with the new APPROX_COUNT_DISTINCT function. The function approximates the count within a 2% precision to the actual answer at a fraction of the time.
Let’s see this in action.
In this example, I am using the AdventureworksDW2016CTP3 sample database which you can download here.
- SET STATISTICS IO ON
- SELECT COUNT(DISTINCT([SalesOrderNumber])) as DISTINCTCOUNT
- FROM [dbo].[FactResellerSalesXL_PageCompressed]
SQL Server Execution Times
- SELECT APPROX_COUNT_DISTINCT ( [SalesOrderNumber]) as APPROX_DISTINCTCOUNT
- FROM [dbo].[FactResellerSalesXL_PageCompressed]
SQL Server Execution Times

You can see the elapsed time is significantly lower! Great improvement using this new function.
The first time I did this, I did it wrong. A silly typo with a major result difference. So take a moment and learn from my mistake.
Note that I use COUNT(DISTINCT(SalesOrderNumber)) not DISTINCT COUNT (SalesOrderNumber ). This makes all the difference. If you do it wrong, the numbers will be way off as you can see from the below result set. You’ll also find that the APPROX_DISTINCTCOUNT will return much slower than the Distinct Count; which is not expected.

Remember COUNT(DISTINCT expression) evaluates the expression for each row in a group and returns the number of unique, non-null values, which is what APPROX_COUNT_DISTINCT does. DISTINCT COUNT (expression) just returns a row count of the expression, there is nothing DISTINCT about it.
Always fun tinkering with something new!

No comments:
Post a Comment
It’s all about friendly conversation here at small review :) I’d love to be hear your thoughts!
Be sure to check back again because I do make every effort to reply to your comments here.