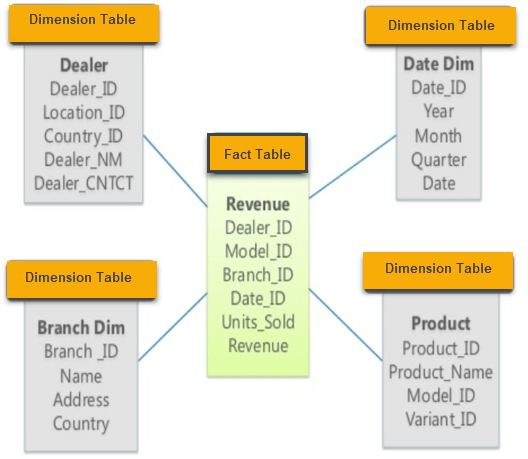
SQL Server Index Terms
Let’s have a chat about your indexes in SQL Server. Indexes can be confusing. They are the easiest way to boost performance of queries, but there are so many options and terms around indexes that it can be hard to keep track of them. Let’s chat about the differences between clustered and Nonclustered indexes, key columns and nonkey columns, and covering and non-covering indexes.
Clustered vs. Nonclustered Indexes
Clustered index: a SQL Server index that sorts and stores data rows in a table, based on key values.
The basic syntax to create a clustered index is
Nonclustered index: a SQL Server index which contains a key value and a pointer to the data in the heap or clustered index.
The basic syntax for a Nonclustered index is
The difference between clustered and Nonclustered SQL Server indexes is that a clustered index controls the physical order of the data pages. The data pages of a clustered index will always include all the columns in the table, even if you only create the index on one column. The column(s) you specify as key columns affect how the pages are stored in the B-tree index structure. A Nonclustered index does not affect the ordering and storing of the data.
A B-tree structure has at least two levels: the root and the leaves. If there are enough records, intermediate levels may be added as well. Clustered index leaf-level pages contain the data in the table. Nonclustered index leaf-level pages contain the key value and a pointer to the data row in the clustered index or heap.

hand-drawn representation of a b-tree.
fine art, folks.
There are a few limits to indexes.
- There can be only one clustered index per table.
- SQL Server supports up to 999 nonclustered indexes per table.
- An index – clustered or nonclustered – can be a maximum of 16 columns and 900 bytes.
These are limits, not goals. Every index you create will take up space in your database. The index will also need to be modified when inserts, updates, and deletes are performed. This will lead to CPU and disk overhead, so craft indexes carefully and test them thoroughly.
Primary Key as a Clustered Index
Primary key: a constraint to enforce uniqueness in a table. The primary key columns cannot hold NULL values.
In SQL Server, when you create a primary key on a table, if a clustered index is not defined and a nonclustered index is not specified, a unique clustered index is created to enforce the constraint. However, there is no guarantee that this is the best choice for a clustered index for that table. Make sure you are carefully considering this in your indexing strategy.
Key vs. Nonkey Columns
Key columns: the columns specified to create a clustered or nonclustered index.
Nonkey columns: columns added to the INCLUDE clause of a nonclustered index.
The basic syntax to create a nonclustered index with nonkey columns is:
A column cannot be both a key and a non-key. It is either a key column or a non-key, included column.
The difference lies in where the data about the column is stored in the B-tree. Clustered and nonclustered key columns are stored at every level of the index – the columns appear on the leaf and all intermediate levels. A nonkey column will only be stored at the leaf level, however.
There are benefits to using non-key columns.
- Columns can be accessed with an index scan.
- Data types not allowed in key columns are allowed in nonkey columns. All data types but text, ntext, and image are allowed.
- Included columns do not count against the 900 byte index key limit enforced by SQL Server.
Covering Indexes
Covering index: all columns returned in a query are in the index, so no additional reads are required to get the data.
A covering index will reduce the IO operations, and improve performance of queries.
Let’s create a query and compare two indexes. I’m creating these on the Product.Products table in the AdventureWorks2012 database.
The query we want to use is
The first index is nonclustered, with two key columns:
The second is also nonclustered, with two key columns and three nonkey columns:
In this case, the first index would not be a covering index for that query. The second index would be a covering index for that specific query.
Indexes Can Be Magic, Except Whey They Aren’t
Indexes are the easiest thing to add to your database to boost performance. However, too much of a good thing can be bad. When designing a database, or troubleshooting poor performance, consider all your index options and carefully test them.